Although FDMEE is the data management tool of the future for Workspace, it is still lacking some of the basic functionality that can be utilized in FDM classic. One of these issues arose recently on my current project: How can we have 2 separate load rules in FDMEE, but have them each pointing to a separate database in the same application? The answer, it seems, is that you can’t. To begin, let me describe the issue in FDMEE in a little more in depth… Read more
Tag Archive for: Data
A Primer for Master Data Management in Finance Organizations
Part I
Overview
You can only improve what you can measure. That popular business maxim, like many others today, is highly dependent upon data. What’s more it can’t be just any data. Quality decisions require “Quality” data that is timely and reliable. Moreover, executives must understand what should be measured, how those measurements are obtained and much more in order to correlate all the data necessary for accurate decision making. After all, that’s the objective, right? Making better decisions faster? Read more
Goodbye to the days of JavaScript in order to enforce data input policies and rules to Planning web forms. With Planning version 11.1.2 and newer, Oracle has introduced a powerful set of tools for data validation within the Planning Data Form Designer itself. Let’s walk through a scenario of how this works.
Say that we have a product mix form that will be used to input percentages as drivers for a revenue allocation. Here’s what the form looks like:
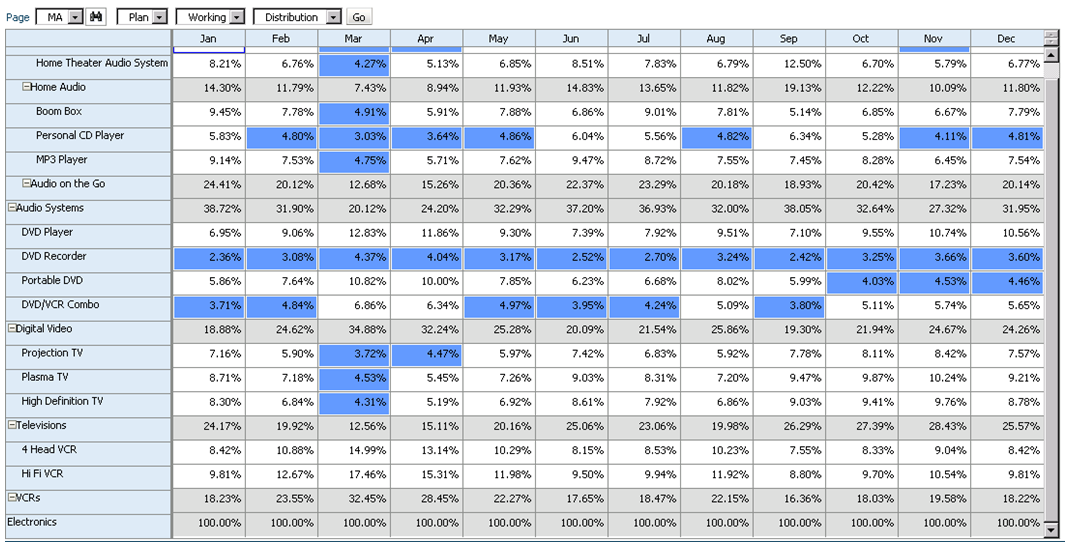
We should expect that the sum of these percentages to be 100% at the “Electronics” parent member. If this is not the case, the revenue allocation will incorrectly allocate data across products. So how do we enforce this rule? Simple… let’s take a look at the data form design.
As a row definition we’ve included two member selections; 1) Descendants(Seg01) or Descendants(Electronics) and 2) Seg01 or Electronics. We are going to add a validation rule to row 2 of the data form. To do this, highlight row 2 and click the sign to add a new validation rule. Notice that in the validation rules section, it now says ‘Validation Rules: Row 2’.

The Data Validation Rule Builder will then be launched. Let’s fill in the rule. We should ensure the Location is set to ‘Row 2’. We’ve filled in a name and quick description, then ensured that the ‘Enable validation rule’ check box is checked.
For the rule we’ve defined some simple if logic:
IF [Current Cell Value] != [Value = 1] THEN [Process Cell] ;
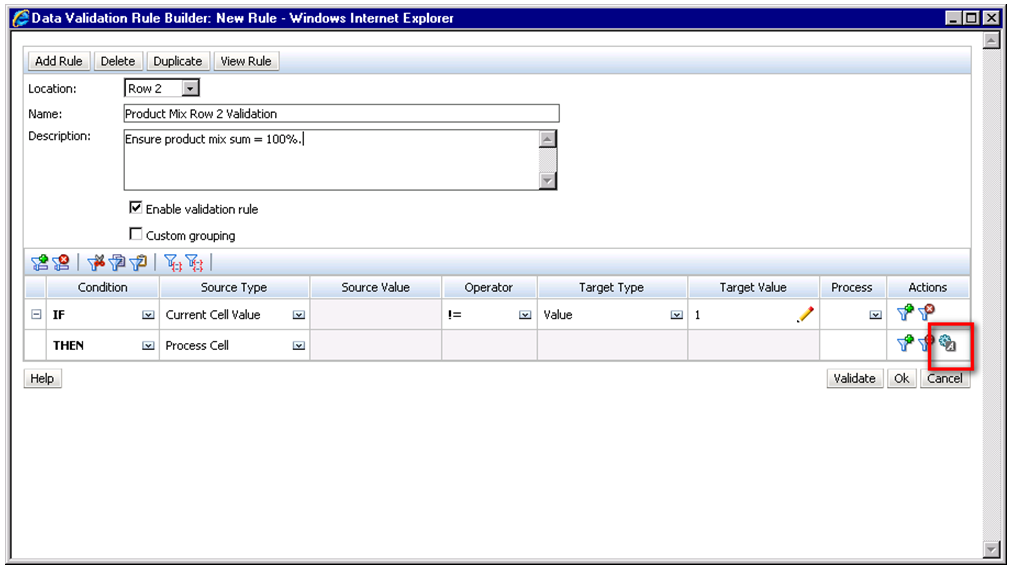
To define what occurs if this condition is met we choose the ‘Process Cell’ action defined by the small gear with a letter A next to it. Here we will highlight the cell red and notify the user with a validation message.

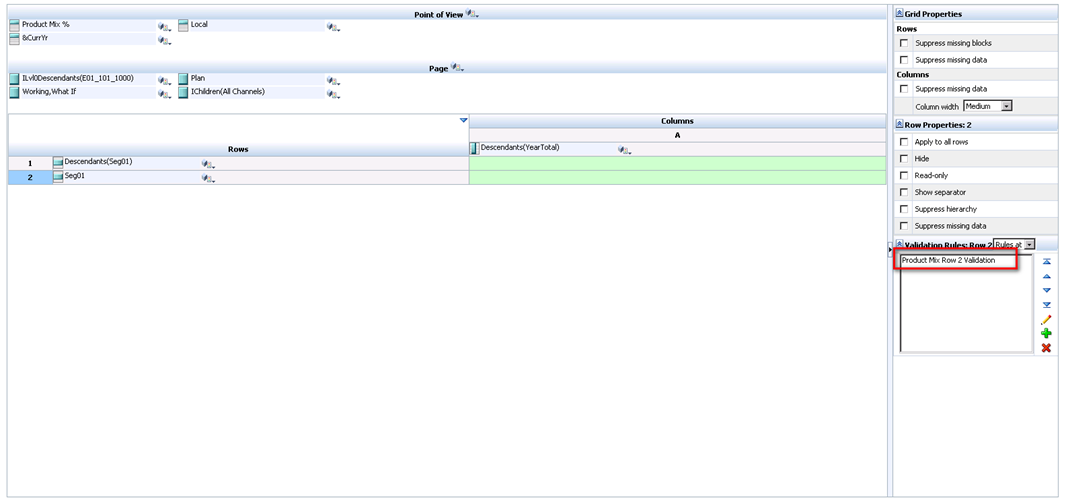
We click through to save the Process Cell definition and the Validation Rule itself and should now see the rule in the data form definition.
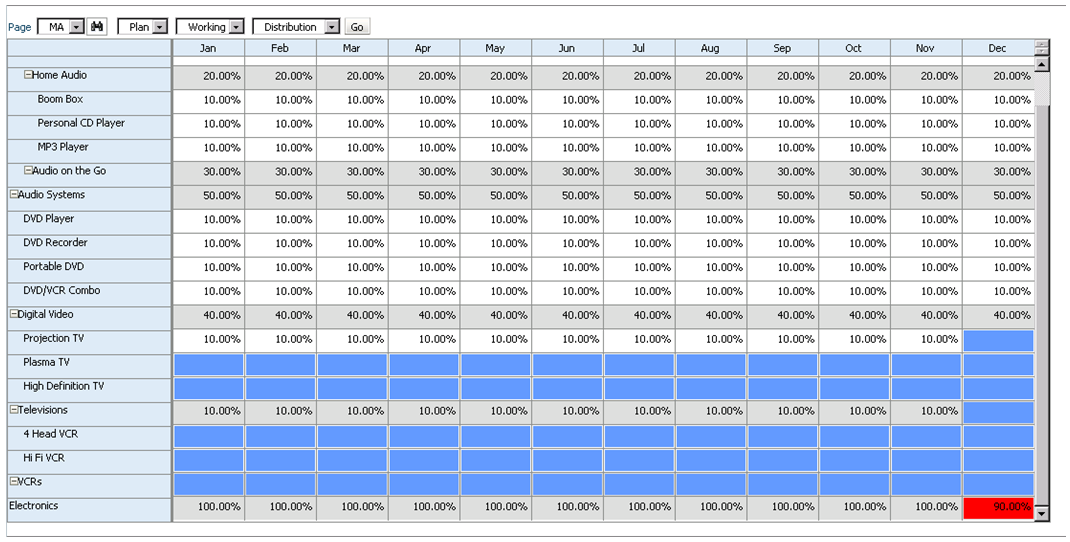
So let’s take a look at how the end user will interact with this form. Percentages are entered by product for each month. Upon save, notice that all months for Electronics that equal 100% appear normal. December only sums to 90% and is highlighted in red as we specified in the data validation rule. We cannot limit the user’s ability to save the form until the cell equals 100%; we can only notify them of the issue, and explain the cause and potential resolutions.
Of course, this is a simple example of what can be done using Planning’s Data Validation Rules. The possibilities are endless. Oracle has more scenario walkthroughs in the Planning Administrator’s Guide. View them here: http://download.oracle.com/docs/cd/E17236_01/epm.1112/hp_admin/ch08.html
The format of the data that is loaded to Essbase is often an after-thought. But, should it be? When requesting the data file from a source system, it is more important than you may think to have it sorted to mirror your outline.
Assume an outline has the following dimensions.
- Period [DENSE]
- Account [DENSE]
- Region [SPARSE]
- Category [SPARSE]
- Product [SPARSE]
- Organization [SPARSE]
The most efficient way to receive a data file would be to have it sorted by Organization, Product, Category, Region, and then Account. Data files load faster when the columns that hold the sparse members are sorted in reverse order of the sparse dimensions that exist in the outline.
The reason the data loads faster is because it opens a block of data only one time. If the data was sorted by the dense members first, then every block would have to be opened multiple times. If the same sparse member combinations have 3,000 dense members with data, the block would be opened up to 3,000 times.
There are some more important benefits of doing this, however. When the block is opened multiple times, the database becomes far more fragmented than it needs to be. Fragmentation causes calculations to be slower and retrieving data can also be impacted, which can lead to frustrated customers.
By not sorting the data when loaded, every time a data load occurs, any performance issues that may exist are exacerbated. So, anytime possible, sort the data load files by the last sparse dimension in the outline, the second to last sparse dimension in the outline, and so on. You may be presently surprised at the benefits.
Whether in a finance organization or a technical role, most of us have had the need to create sample data to use to test Hyperion systems. In2Hyperion is sharing a tool to make this process more efficient. By defining a numeric range, the number of columns, and the number of rows, an excel spreadsheet will be generated with the appropriate random data.
This tool can be access at http://www.in2hyperion.com/Tools/RandomNumbers.aspx.