Oracle has confirmed a bug related to the deployment of security with a planning application maintained in EPMA in version 11.1.2.x. When the Shared Members checkbox is selected in an EPMA deployment of a Planning application, it ignores this option. Even if the Shared Members box is checked, the user still only gets access to Ohio Region, and not the children, in the example below. Oracle is currently working on a patch. Read more
Tag Archive for: planning
The introduction of Hyperion 11.1.2 has some fantastic improvements. Many of these have been long awaited. The next few articles on In2Hyperion will describe some of the enhancements to Hyperion Planning, Hyperion Essbase, and Hyperion SmartView.
XREF Background
If you have been developing Planning applications, you are probably very familiar with the XREF function. This function is used in business rules, calculation scripts, and member formulas. It provides a method to move data from one plan type (Essbase database) to another plan type. It is executed from the target database and pulls the data from the source. XWRITE was actually introduced in later versions of 11.1.1.x, but is very stable in 11.1.2.x. XWRITE is executed from the source and pushes data to the target. This function is a huge improvement over XREF. Read more
Although implied shares can improve performance by not storing the same data multiple times, it has many negative impacts. For example, implied shares cause problems in Hyperion Planning at the load level (level 0). A parent with a storage property of Stored that has one child (or only one child that consolidates) will create an implied share. This results in level 0 members being locked, preventing web form data entry. In Essbase/Planning, the storage method of any parent with one child has to be changed to Never Share to allow user input.
For those of you who have been snake bitten by this, you will welcome a relatively unknown Essbase configuration setting in the Essbase configuration file (essbase.cfg). Read more
KScope12 is the premier conference for Hyperion techies and up-and-comers. Whether you are looking to brush up on your skills, learn new skills, or see how others overcome challenges, you will want to participate in this event. If your organization values your development and has a budget for these growth opportunities, mark your calendar for June 24th through the 28th. Registration is open, and as more information is available, it will be published at In2Hyperion.
Presenting a topic is a great way to reduce the cost of the trip. It’s a great way to get your name out in the community as well. If you have something that you think would be valuable for other experts to hear about, submit an abstract.
We hope to see you there. Visit www.kscope12.com for all travel details and abstract submissions.
Goodbye to the days of JavaScript in order to enforce data input policies and rules to Planning web forms. With Planning version 11.1.2 and newer, Oracle has introduced a powerful set of tools for data validation within the Planning Data Form Designer itself. Let’s walk through a scenario of how this works.
Say that we have a product mix form that will be used to input percentages as drivers for a revenue allocation. Here’s what the form looks like:
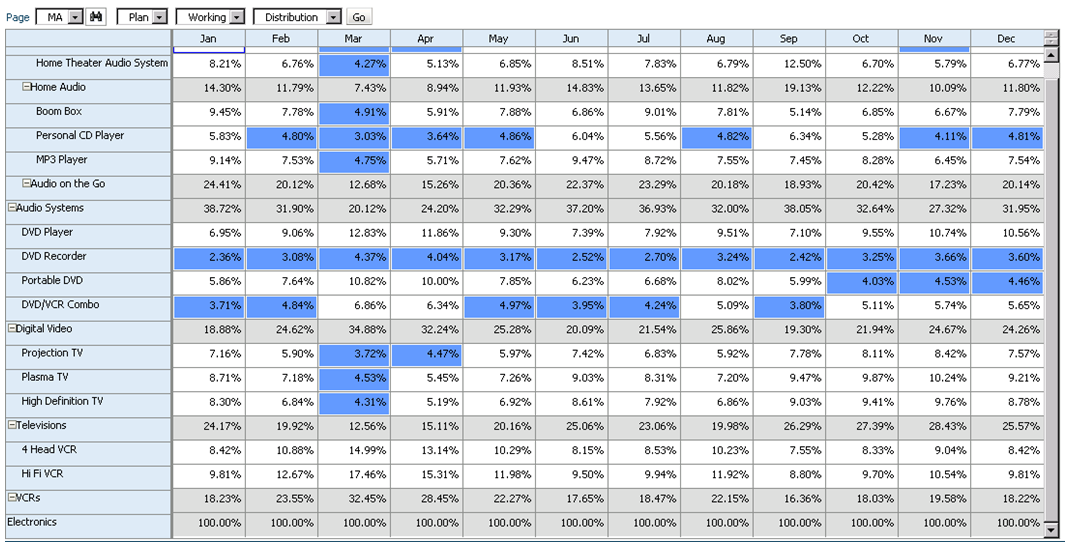
We should expect that the sum of these percentages to be 100% at the “Electronics” parent member. If this is not the case, the revenue allocation will incorrectly allocate data across products. So how do we enforce this rule? Simple… let’s take a look at the data form design.
As a row definition we’ve included two member selections; 1) Descendants(Seg01) or Descendants(Electronics) and 2) Seg01 or Electronics. We are going to add a validation rule to row 2 of the data form. To do this, highlight row 2 and click the sign to add a new validation rule. Notice that in the validation rules section, it now says ‘Validation Rules: Row 2’.

The Data Validation Rule Builder will then be launched. Let’s fill in the rule. We should ensure the Location is set to ‘Row 2’. We’ve filled in a name and quick description, then ensured that the ‘Enable validation rule’ check box is checked.
For the rule we’ve defined some simple if logic:
IF [Current Cell Value] != [Value = 1] THEN [Process Cell] ;
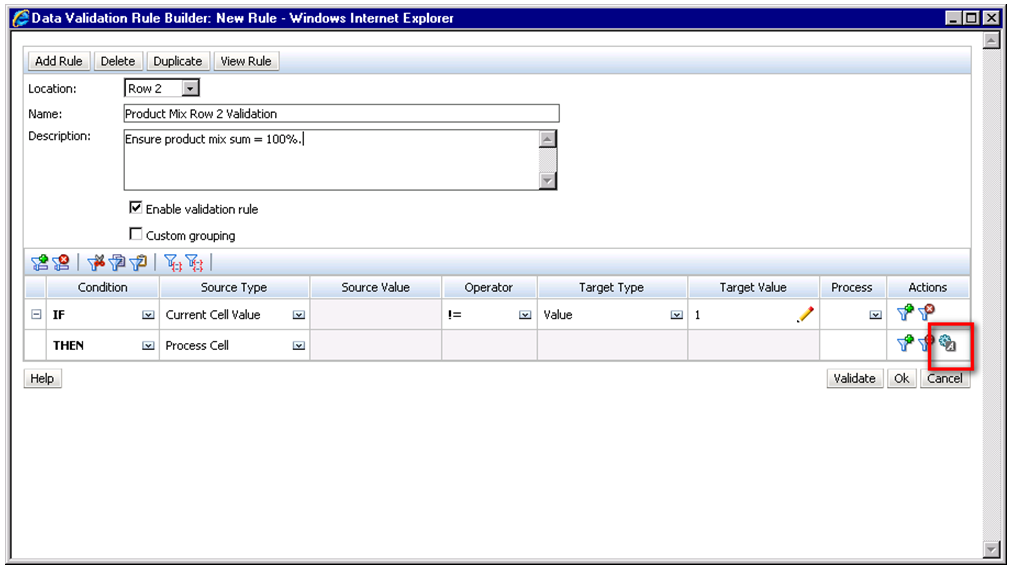
To define what occurs if this condition is met we choose the ‘Process Cell’ action defined by the small gear with a letter A next to it. Here we will highlight the cell red and notify the user with a validation message.

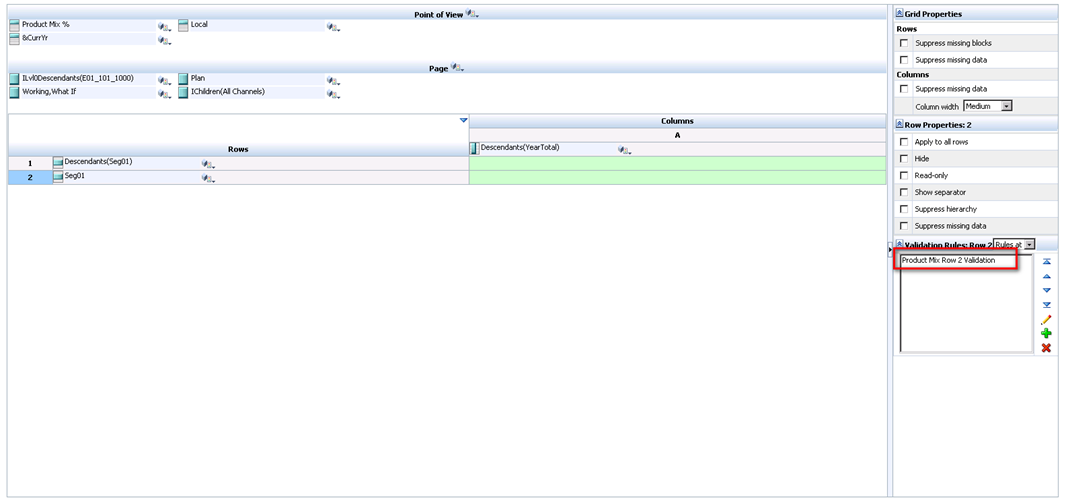
We click through to save the Process Cell definition and the Validation Rule itself and should now see the rule in the data form definition.
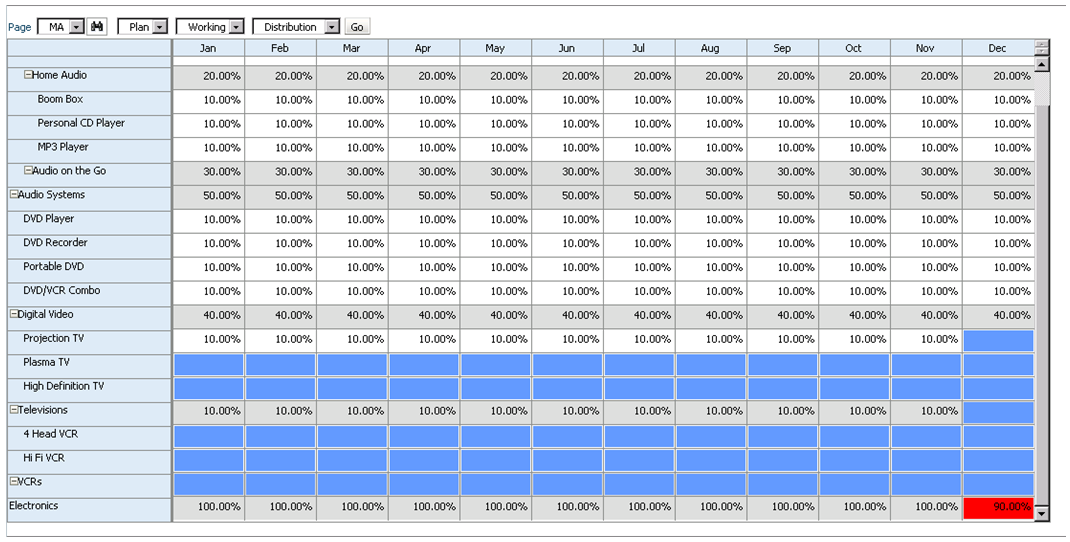
So let’s take a look at how the end user will interact with this form. Percentages are entered by product for each month. Upon save, notice that all months for Electronics that equal 100% appear normal. December only sums to 90% and is highlighted in red as we specified in the data validation rule. We cannot limit the user’s ability to save the form until the cell equals 100%; we can only notify them of the issue, and explain the cause and potential resolutions.
Of course, this is a simple example of what can be done using Planning’s Data Validation Rules. The possibilities are endless. Oracle has more scenario walkthroughs in the Planning Administrator’s Guide. View them here: http://download.oracle.com/docs/cd/E17236_01/epm.1112/hp_admin/ch08.html
Everybody knows the quickest way from point A to point B is a straight line. Everybody assumes that the path is traveled only one time – not back and forth, over and over again. I see a lot of Essbase calculations and business rules, from experienced and novice developers, that go from point A to point B taking a straight line. But, the calculation travels that line multiple times and is terribly inefficient.
Here is a simple example of a calculation. Assume the Account dimension is dense, and the following members are all members in the Account dimension. We will also assume there is a reason to store these values rather than making them dynamic calc member formulas. Most of these are embedded in a FIX statement so the calculation only executes on the appropriate blocks. To minimize confusion, this will not be added to the example.
Average Balance = (Beginning Balance Ending Balance) / 2; Average Headcount = (Beginning Headcount Ending Headcount) / 2; Salaries = Average Headcount * Average Salaries; Taxes = Gross Income * Tax Rate;
One of the staples of writing an effective calculation is to minimize the number of times a single block is opened, updated, and closed. Think of a block as a spreadsheet, with accounts in the rows, and the periods in the columns. If 100 spreadsheets had to be updated, the most efficient way to update them would be to open one, update the four accounts above, then save and close the spreadsheet (rather than opening/editing/closing each spreadsheet 4 different times for each account).
I will preface by stating the following can respond differently in different version. The 11.1.x admin guide specifically states the following is not accurate. Due to the inconsistencies I have experienced, I always play it safe and assume the following regardless of the version.
You might be surprised to know that the example above passes through every block four times. First, it will pass through all the blocks and calculate Average Balance. It will then go back and pass through the same blocks again, calculating Average Headcount. This will occur two more times for Salaries and Taxes. This is, theoretically, almost 4 times slower than passing through the blocks once.
The solution is very simple. Simply place parenthesis around the calculations.
( Average Balance = (Beginning Balance Ending Balance) / 2; Average Headcount = (Beginning Headcount Ending Headcount) / 2; Salaries = Average Headcount * Average Salaries; Taxes = Gross Income * Tax Rate; )
This will force all four accounts to be calculated at the same time. The block will be opened, all four accounts will be calculated and the block will be saved.
If you are new to this concept, you probably have done this without even knowing you were doing it. When an IF statement is written, what follows the anchor? An open parenthesis. And, the ENDIF is followed by a close parenthesis. There is your block!
"East" (IF(@ISMBR("East")) "East" = "East" * 1.1; ENDIF)
I have seen this very simple change drastically improve calculations. Go back to a calculation that can use blocks and test it. I bet you will be very pleased with the improvement.
Almost every planning or forecasting application will have some type of allocation based on a driver or rate that is loaded at a global level. Sometimes these rates are a textbook example of moving data from one department to another based on a driver, and sometimes they are far more complicated. Many times, whether it is an allocation, or a calculation, rates are entered (or loaded) at a higher level than the data it is being applied to.
A very simple example of this would be a tax rate. In most situations, the tax rate is loaded globally and applied to all the departments and business units (as well as level 0 members of the other dimensions). It may be loaded to “No Department”, “No Business Unit”, and a generic member in the other custom dimensions that exist.
If a user needs the tax rate, in the example above, they have to pull “No Department” and “No Business Unit.” Typically, users don’t want to take different members in the dimension to get a rate that corresponds to the data (Total Department for taxes, and No Department for the rate). They want to see the tax rate at Total Department, Total Business Unit, and everywhere in-between.
There are a number of ways to improve the experience for the user. An effective solution is to have two members for each rate. One is stored and one is dynamic. There is no adverse effect on the number of blocks, or the block size. The input members can be grouped in a hierarchy that is rarely accessed, and the dynamic member can be housed in a statistics hierarchy.
Using tax rate in the example above, create a “Tax Rate Input” member. Add this to a hierarchy called “Rate Input Members”. Any time data is loaded for the tax rate; it is loaded to Tax Rate Input, No Department, No Business Unit, etc. Under the statistics/memo hierarchy, create a dynamic member called “Tax Rate”. “Tax Rate” would be the member referenced in reports. The formula for this includes a cross-dimensional reference to the “Tax Rate Input” member, and would look something like this.
“No Department”->”No Business Unit”->”Tax Rate Input”;
When a user retrieves “Tax Rate”, it always returns the rate that is loaded to “No Department,” “No Business Unit,” and “Tax Rate Input,” no matter what department or business unit the report is set to. The effort involved in creating reports in Financial Reporting or Smart View now becomes easier!
There is an added bonus for the system administrators. Any calculation that uses the rate (you know, the ones with multi-line cross-dimensional references to the rates) is a whole lot easier to write, and a whole lot easier to read because the cross-dimensional references no longer exist.
Before you move the application to production, make sure to set the input rates consolidation method to “Never.” Don’t expect this change to make great improvements in performance, but it will cause the aggregations to ignore these members when consolidating the hierarchies. A more important benefit is that users won’t be confused if they ever do look at the input rates at a rolled up level. The ONLY time they would see the rate would be at level 0, and would be an accurate reflection of the rate.
Note: It is recommended to create member names without spaces. The examples above ignored this rule in an effort to create an article that is more readable.
What’s New in Hyperion 11.1.2?
Shared Services
As you’ve no doubt noticed by now, this has turned into a series of posts involving new features in the 11.1.2 release of the Hyperion products. This post will cover some of the significant changes to Shared Services, including improvements to Security Administration, Lifecycle Management, and Taskflows.
Security Administration
It’s been well-documented at this point that there have been multiple issues with the OpenLDAP approach to the Native Directory. In 11.1.2, the OpenLDAP has been replaced with a relational database as the storage point for native accounts and provisioning. This has already proven beneficial, as it allows for the next improvement below.
There is no longer a need for Essbase synchronization for users, as it is now done automatically. This is a welcome change from most, as it was always very easy to forget to refresh security. However, group synchronization must still be done manually.
The supported SSL configurations have also seen significant improvements. These include:
- SSL Offloading
- 2-way SSL deployment
- SSL termination at the web server
Oracle Single Sign-On (OSSO) is also supported in this release. The Oracle Internet Directory (OID) is used to provide SSO access to web applications.
Lifecycle Management (LCM)
Like the rest of Shared Services, LCM has adopted Oracle Diagnostics Logging (ODL) as the standard logging mechanism.
Perhaps the biggest improvement to LCM is that it now supports the extraction of data. Essbase data now appears as a selectable artifact when performing an export, and can be updated with the outline. On this note, I should probably point out that for cross-product migrations, LCM determines the correct order based on dependencies.
Some other modifications to LCM include:
- Additional information in migration status reports, including source and destination details.
- Users must be provisioned with the Shared Services Administrator role to work with the Deployment Metadata tool.
- The Calc Manager is supported, and has its own node under Foundation. As a result, business rules can now be migrated to classic HFM and Planning applications.
Shared Services Taskflow
This release has seen the addition of two new roles in Shared Services
- Manage Taskflows – This role allows users to create and edit a taskflow
- Run Taskflows – This role permits users to view and run a taskflow, but they cannot create or edit taskflows
Follow the link below to view the complete document of changes
There is, what appears to be, a bug in Hyperion Planning that causes business rules that take longer than 5 minutes to re-launch. The following, published by Oracle, explains the root issue of this problem. It is not a bug, but a setting in the host web server that causes the request post multiple times. This explaination from Oracle clearly states that this is ONLY an issue when accessing Hyperion Planning through Hyperion Workspace. I have seen the same response while accessing Hyperion Planning directly. Regardless of your entry point, it is a good proctice account for either entry method and should be applied.
This applies to Hyperion Planning, Version: 9.3.1.0.00 to 11.1.1.3.00 and is applicable to all operating systems.
Symptoms
When accessing Planning, Business Rules that normally take more than 5 minutes to complete
run for an unlimited period of time. By viewing the running Essbase sessions in the EAS console, you can see that the Business Rules “Calculate” sessions are being re-launched every 5 minutes, so that a new instance of the Rule is launched before the first can complete.
This issue only affects Business Rules that normally take more than 5 minutes to complete.
This issue does not affect Business Rules launched directly from Planning (accessing Planning directly on its own URL, bypassing the Workspace). This issue does not affect Business Rules launched from the EAS console. This issue only affects systems using Weblogic as a web application server.
Cause
This issue is caused by a default timeout setting of 5 minutes (300 seconds) in the Weblogic HTTP Server Plugin. This plugin is a set of configuration files in which Weblogic defines how it will interact with the HTTP Server through which Workspace is accessed. More information on Weblogic Plugins is available here: http://download.oracle.com/docs/cd/E13222_01/wls/docs92/pdf/plugins.pdf
Solution
Hyperion System 9 and Oracle EPM 11.1.1.x support the use of either Microsoft Internet Information Services (IIS) or Apache as an HTTP server. The steps to increase the timeout depend on which you are using. The new timeout value should be set to a value larger than the time the longest-running Business Rule takes to execute. The examples below use a setting of 30 minutes (1800 seconds).
Apache HTTP Server
Step 1
Edit %HYPERION_HOME%\common\httpServers\Apache\2.0.52\conf\HYSL-WebLogic.conf
Step 2
Add (or edit, if already present) the following parameters to the two sections for Planning, and also to the two sections for Financial Reporting and Workspace, as the 5 minute timeout issue can cause problems in all three products.Each section begins with an XML tag.
WLIOTimeoutSecs 1800 HungServerRecoverSecs 1800 <LocationMatch /HyperionPlanning> <LocationMatch /HyperionPlanning/*>
Add the new “WLIOTimeoutSecs 1800” and “HungServerRecoverSecs 1800” properties as new lines within the tags. If you are using a version of Weblogic prior to 9.x you need to add the second line “HungServerRecoverSecs 1800” in addition to the “WLIOTimeoutSecs 1800” parameter. This second parameter is not necessary for Weblogic 9.x and later (though it will do no harm).
PathTrim / KeepAliveEnabled ON KeepAliveSecs 20 WLIOTimeoutSecs 1800 HungServerRecoverSecs 1800
Internet Information Services (IIS)
Step 1
There are several copies of the iisproxy.ini file. Oracle recommends you modify the files for Planning, Financial Reporting and Workspace, as the 5 minute timeout issue can cause problems in all three products.
Paths (note that “hr” below stands for Financial Reporting):
%HYPERION_HOME%\deployments\WebLogic9\VirtualHost\hr
%HYPERION_HOME%\deployments\WebLogic9\VirtualHost\HyperionPlanning
%HYPERION_HOME%\deployments\WebLogic9\VirtualHost\workspace
Step 2
For each copy of iisproxy.ini, add the following lines at the end of each file. If you are using a version of Weblogic prior to 9.x you need to add the second line “HungServerRecoverSecs=1800” in addition to the “WLIOTimeoutSecs=1800” parameter. This second parameter is not necessary for Weblogic 9.x and later (though it will do no harm).
WLIOTimeoutSecs=1800
HungServerRecoverSecs=1800
Step 3
Restart IIS from the IIS Manager and restart the Workspace web application service
Oracle HTTP Server is used
Step 1
Modify the file mod_wl_ohs.conf file under the directory, $EPM_ORACLE_INSTANCE\httpConfig\ohs\config\OHS\ohs_component with the following content:
<LocationMatch ^/HyperionPlanning/> SetHandler weblogic-handler WeblogicCluster PlaningServer:8300 WLIOTimeoutSecs -1 WLSocketTimeoutSecs 600 </LocationMatch>
Step 2
Restart the Oracle HTTP server and the Workspace web application services after the modifications are complete.
Changes to an Essbase outline cause changes to the Essbase index and data files, regardless of the method (Essbase Administration Services, Hyperion Planning database refreshes, or from a script).
Changes that require restructuring the database are time-consuming (unless data is discarded before restructuring). Understanding the types of restructures and what causes them can help database owners more effectively manage the impacts to users.
TYPES OF RESTRUCTURES
Essbase initiates an implicit restructure after an outline is changed, whether done with the outline editor, through an automated build, or some other fashion like a Hyperion Planning database refresh. The type of restructure that is performed depends on the type of changes made to the outline.
DENSE RESTRUCTURE: If a member of a dense dimension is moved, deleted, or added, Essbase restructures the blocks in the data files and creates new data files. When Essbase restructures the data blocks, it regenerates the index automatically so that index entries point to the new data blocks. Empty blocks are not removed. Essbase marks all restructured blocks as dirty, so after a dense restructure you must recalculate the database. Dense restructuring, the most time-consuming of the restructures, can take a long time to complete for large databases.
SPARSE RESTRUCTURE: If a member of a sparse dimension is moved, deleted, or added, Essbase restructures the index and creates new index files. Restructuring the index is relatively fast; the time required depends on the index size.
Sparse restructures are typically fast, but depend on the size of the index file(s). Sparse restructures are faster than dense restructures.
OUTLINE ONLY: If a change affects only the database outline, Essbase does not restructure the index or data files. Member name changes, creation of aliases, and dynamic calculation formula changes are examples of changes that affect only the database outline.
Outline restructures are very quick and typically take seconds.
Explicit restructures occur when a user requests a restructure to occur. This can be done in Essbase Administration Services or via Maxl (and EssCmd for those of you who still use it) and forces a full restructure (see dense restructure above). It is worth noting that this also removes empty blocks.
CALCULATING IMPLICATIONS AFTER RESTRUCTURES
When a restructure occurs, every block that is impacted is tagged as dirty. If Intelligent Calculations are used in the environment, they don’t provide any value when a dense restructure occurs as all blocks will be calculated. When member names or formulas are changed, the block is not tagged as dirty.
WHAT DICTATES THE RESTRUCTURE TYPE
The following outline changes will force a dense restructure, which is the most time- consuming restructure.
DENSE AND SPARSE
- Defining a regular dense dimension member as dynamic calc
- Defining a sparse dimension regular member as dynamic calc or dynamic calc and store
- Defining a dense dimension dynamic calc member as regular member
- Adding, deleting, or moving dense dimension dynamic calc and store members
- Changing dense-sparse properties [Calc Required]
- Changing a label only property [Calc Required]
- Changing a shared member property [Calc Required]
- Changing the order of dimensions [Calc Required]
DENSE (DATA FILES)
- Deleting members from a dense dimension [Calc Required]
- Adding members to a dense dimension
- Defining a dense dynamic calc member as dynamic calc and store member
SPARSE (INDEX)
- Adding members to a sparse dimension
- Moving members (excluding shared members) in a sparse dimension
- Defining a dense dynamic calc member as dynamic calc and store
- Adding, deleting, or moving a sparse dimension dynamic calc member
- Adding, deleting, or moving a sparse dimension dynamic calc and store member
- Adding, deleting, or moving a dense dimension dynamic calc member
- Changing the order of two sparse dimensions
NO RESTRUCTURE OCCURS
- Deleting members of a sparse dimension [Calc Required]
- Deleting members of an attribute dimension
- Deleting shared members from a sparse or dense dimension [Calc Required]
- Adding members to an attribute dimension
- Adding shared members to a sparse or dense dimension
- Moving a member in an attribute dimension
- Renaming a member
- Changing a member formula [Calc Required]
- Defining a sparse dynamic calc member as dynamic calc and store member
- Defining a dense or sparse dynamic calc and store member as dynamic calc
- Defining a regular dense dimension member as dynamic calc and store
- Defining a sparse dimension dynamic calc and store member or dynamic calc member as regular member
- Defining a dense dimension dynamic calc and store member as regular member
- Changing properties other than dense-sparse, label, or shared [Calc Required]
- Changing the order of an attribute dimension
- Creating, deleting, clearing, renaming, or coping an alias table
- Importing an alias table
- Setting a member alias
- Changing the case-sensitive setting
- Naming a level or generation
- Creating, changing, or deleting a UDA
WHAT DOES THIS MEAN
Understanding this can help users and administrators manage applications to better meet the needs of all those involved. When designing an application, knowledge of this topic can be instrumental in the success of the application. Here are some things to keep in mind.
- When updating an outline or refreshing a planning application, it may be faster to export level 0 (or input level) data, clear the data, perform the update, and reload/aggregate the export when changes cause a dense restructure.
- For dimensions that are updated frequently, it may be beneficial to define those dimensions as sparse. Changes to sparse dimensions typically require only restructures to the index file(s), which are much faster.
- If frequent changes are required, enabling incremental restructuring may make sense. Using this defers dense restructures. The Essbase restructure happens on a block by block basis, and occurs the first time the data block is used. The cost is that calculations will cause restructures for all the blocks included and the calculation performance will degrade.
- Setting the isolation level to committed access may increase memory and time requirements for database restructure. Consider setting the isolation level to uncommitted access before a database restructure.
- If multiple people have access to change the outline, outline logging may be useful. This can be turned on by adding OUTLINECHANGELOG = TRUE in the essbase.cfg.
- Monitoring progress of a restructure is possible when access to the server is granted. Both sparse and dense restructures create temporary files that mirror the index and data files. Data exists in the .pag files while indexes are stored in .ind files. As the restructure occurs, there are equivalent files for each (pan for data files and inn for index files). In total, the restructure should decrease the size of the ind and pag files, but the pan and inn files can be used for a general idea of the percent of completion.